

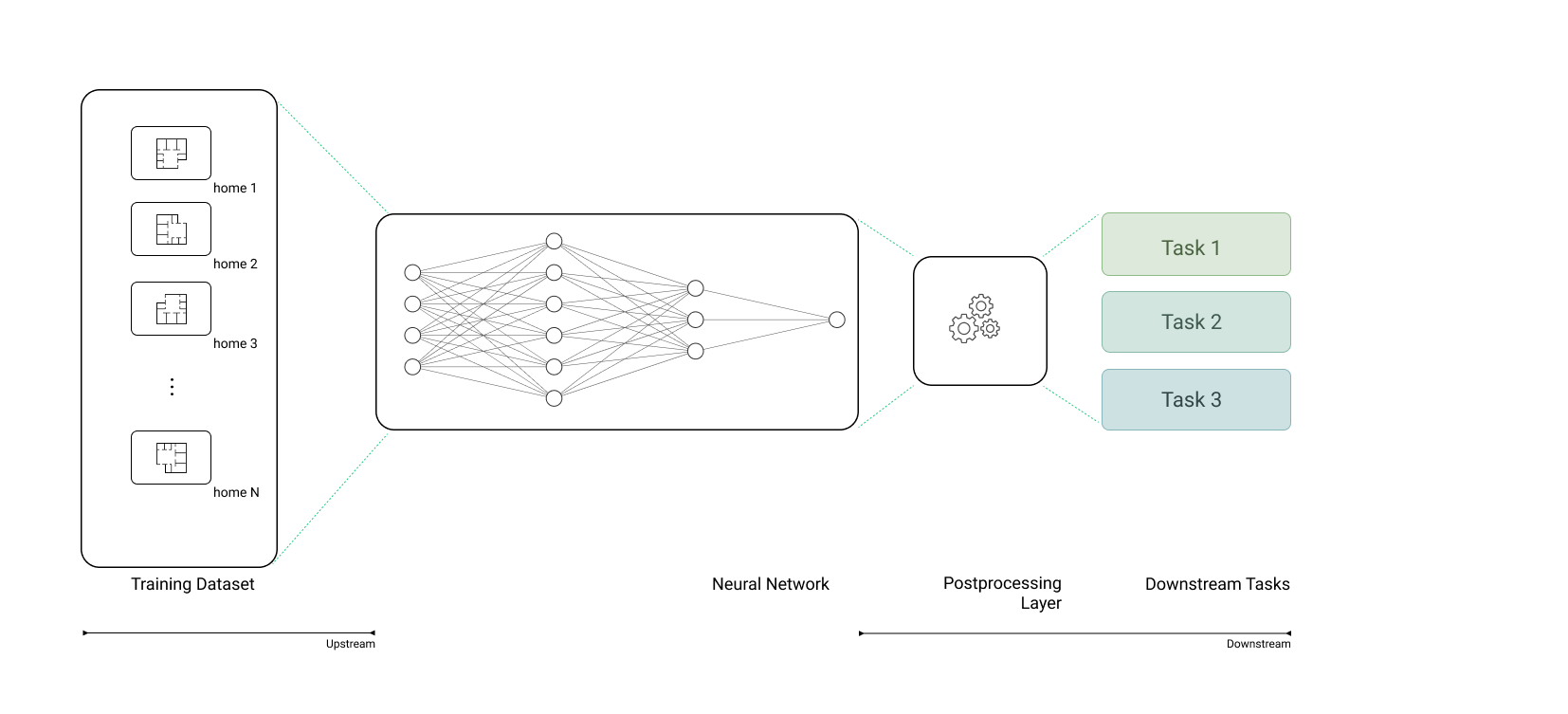
Generative Building Model, or GBM, is Higharc’s AI home design and layout model. Its lead AI/ML engineer, Manuel Rodriguez Ladron de Guevara, conceived and developed GBM in collaboration with Jinmo Rhee and myself. At the center of the project was a difficult research question: when developing AI for homebuilding, what happens when you represent buildings more like language?
AI still struggles in architecture, engineering and construction (AEC), where failures aren’t simply a matter of refining a prompt or waiting for the next model release. A hallucination in a structural floorplan can have a direct impact on materials, work, cost and even safety.
So when we decided to create Generative Building Model, the starting point was fundamental: how do you encode BIM-native building data so a model can generate layouts without throwing away the geometry, topology and semantic structure that make those layouts safe and usable in real home design workflows? Our research made it very clear that the bottleneck in layout reasoning is not just the model class, but the representation the model operates on.
In this interview, I sit down with Manuel to discuss how Higharc approached this problem, why representation mattered more than inventing a new neural network architecture and what “buildings as language” unlocks for AI home design.
Q: Before getting into GBM itself, what practical problem were you trying to solve with AI layout in a BIM-native home design workflow?
A: At a practical level, I was trying to solve a mismatch between how homebuilders actually work and how most AI layout systems reason. In a real BIM workflow, a layout isn’t just supposed to look plausible. It has to stay editable. It has to respect geometry. It has to survive downstream coordination. And it has to make sense as part of a broader production system, not just as a one-off image.
Traditional CAD and BIM tools are powerful authoring tools, but they don’t really learn from the thousands of rooms and plans a builder has already produced. On the other side, a lot of AI layout systems produce things that look interesting at first glance, but once you ask whether they respect circulation, clearances, doors and windows or real building constraints, they break down.
So the practical problem was: can we build an AI layout model for home design that actually works inside a BIM-native environment? If that becomes reliable enough for implementers to use, it can take repetitive work out of the workflow and save implementation time. Not just a model that makes pretty outputs, but one that learns from real building data and produces layouts that hold up in real workflows.
Q: You’ve said this is fundamentally a representation problem, not just about using Transformers. What do you mean by that?
A: What I mean is that the deepest problem was upstream of the neural network. It was in the form of the data itself.
If you represent a room as an image, a mask or some loose abstraction, you may preserve appearance or maybe some adjacency information, but you often lose the geometric structure that makes the room architectural. You lose the fact that a door is attached to a specific wall, or the difference between a room-level attribute and an entity-level attribute. You lose the precise references that make the result editable and valid in BIM. It’s basically a data-structure decision: a raster image represents space as values on a grid, but it doesn’t natively encode the semantic entities and relationships the model needs to reason about architecture correctly.
That’s why I frame this as a representation problem. The real challenge was to find a way of expressing building structure so the model could reason over it without discarding the very information that matters most. In development of GBM, progress was limited less by the algorithms themselves than by the representations they operated on, and that’s still how I think about it. Once the representation is wrong, a better model just learns the wrong thing more efficiently.
Q: What led you to start thinking about BIM data as something that could be structured more like language?
A: The seed really came from spending time around language-model ideas and asking what makes them so effective. Also, I’m probably biased toward natural language because of my PhD work at Carnegie Mellon. I’d already worked on the intersection of language and design intent.
What fascinated me wasn’t just next-token prediction by itself, but the fact that a very rich structure can emerge from sequences when the tokenization is good enough. Language is obviously not geometry, but it is a domain where meaning survives because the units and their ordering preserve structure.
At some point, I started looking at BIM data through that lens. Buildings are spatial, of course, but BIM data is also deeply organized. A room has a type, global layout properties, an envelope, doors and windows attached to specific walls, and then contents that live relative to that structure. Once I started thinking in those terms, the idea of “buildings as language” stopped sounding like a metaphor and started sounding like a representational question. Could a room be serialized in a way that kept the relationships that matter? That was the real beginning for me.
Q: What specific parallel between language and buildings felt technically useful to you at the time: hierarchy, composition, sequence or something else?
A: The parallel that felt real was hierarchy and composition.
In language, meaning isn’t stored in isolated words. It comes from composition across multiple levels. Buildings are similar in that sense. A room isn’t just a collection of objects. It has room-level semantics, a boundary structure, openings and entities whose meaning depends on how they attach to that structure. What made the analogy feel useful was the idea that you could preserve that composition in a sequential form.
Text can be structured hierarchically as paragraphs, which contain sentences, which contain words, which contain characters. I realized that buildings have a similar hierarchical graph: homes contain levels, which contain zones, blocks or other semantic room groupings, which contain entities (such as doors, windows, furniture, etc.)
Like in language, sequence mattered too, but not in the simplistic sense of “just line things up.” What mattered was finding an ordering logic that reflected architectural dependencies. In our case, that became an envelope sequence and an entity sequence. The room type and layout come first, then the wall structure. Then the openings attach to those walls. Then the contents are generated relative to that encoded envelope. Technically, I had to encode those with a special indexing logic, similar to how the positional encoding works in text inputs.
So for me, the important analogy wasn’t “buildings as language.” It was that both language and buildings are structured, hierarchical systems in which composition matters and a sequence can carry that structure if designed correctly.
The important analogy was that both language and buildings are structured, hierarchical systems in which composition matters and a sequence can carry that structure if designed correctly.
Q: At what point did the language analogy become a workable modeling strategy for BIM-native data?
A: It stopped being an analogy once I could write a room down in a way that felt faithful to architecture.
The big turning point was decomposing a room into envelope and contents, then parameterizing openings and entities relative to explicit structural elements rather than absolute coordinates floating in space. Once a door is attached to a specific wall, and once an entity like a cabinet or a bed is defined by a supporting wall, a normalized position, an offset, a size and an orientation, you’re no longer speaking metaphorically. You have a concrete sequential representation of a BIM-native structure. But in practical terms, it took me a while to figure out how to align both parts — envelope and entities — in a consistent way when writing the code.
That was the moment it became operational for me. Now the encoder could process the room envelope, the decoder could generate the room contents and every token could correspond to a logical building element rather than an arbitrary chunk of data. That’s when the idea felt less like inspiration from NLP and more like a viable modeling strategy for floor plan generation inside BIM workflows.
Q: Why did you think that the hard part was the representation of the data, not inventing a new neural network architecture?
A: Because by that point, it was already known that transformers are very good at learning from sequentially organized data. I didn’t think the bottleneck was that we needed some radically new backbone before we could make progress. My view was that no one had really given the model the right version of the building to learn from.
The novelty isn’t “we invented a magical new neural net.” The novelty is the normalized BIM tokenization, the sparse feature representation and the mixed-type embedding that lets categorical and continuous architectural attributes live together without collapsing them into one crude format.
That was the key conviction for me: if the representation is faithful, a strong sequential model can do a lot. If the representation is distorted, even a more sophisticated model is still reasoning over a distorted building.
Q: Why didn’t you start with image generation or diffusion, especially given how much public attention those models were already getting?
A: Because it felt like a detour away from the data we actually had.
BIM already gives you semantics, hierarchy, constraints and geometric relationships. If you compress that into an image and then ask a model to re-infer the structure out of those pixels, you’ve thrown away the most valuable part of the signal before the learning even starts. That can be useful if your goal is concept imagery or visual ideation. It’s much less appealing if your goal is BIM-native layout generation that remains editable and valid downstream.
That was my discomfort with starting from diffusion models or image generation. Those systems can be visually impressive, but in our setting, they often operate on unstructured geometry or image space, which makes the outputs harder to edit and more prone to validity errors. For Higharc’s use case, I wanted the model to stay as close as possible to the actual building structure from the beginning.
Q: What had to be preserved when you serialized a room so that it remained architecturally meaningful to the model?
A: A lot had to survive, and that is exactly why I prefer the word serialize over flatten.
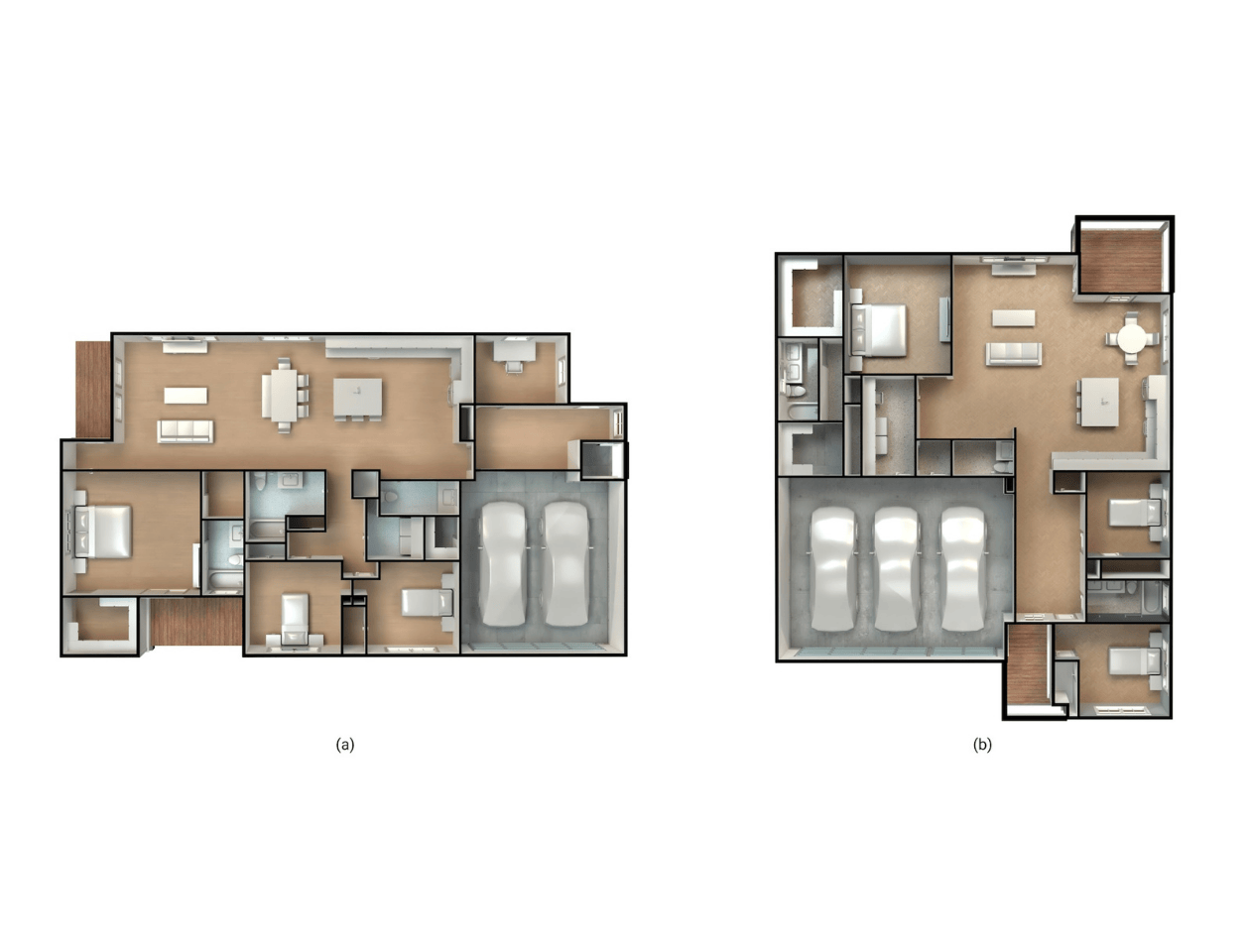
The room type had to survive. The global layout attributes had to survive. The wall structure had to survive, including ordering, wall type, thicknesses, etc., because topology lives there. Doors and windows had to remain attached to specific walls with normalized positions along those walls. And room contents had to remain wall-referenced as well, with explicit information about supporting wall, position, offset, size and orientation.
Just as importantly, I didn’t want to force every token into the same kind of representation. Buildings are heterogeneous. Some features are categorical. Some are scalar continuous values. Some are grouped continuous features. Preserving that heterogeneity was part of preserving the architecture. Once you lose those distinctions, you may still have a sequence, but it’s no longer a faithful representation of the room.
How did your background as an architect shape the product side of this work, especially the need for human intervention during generation?
My architectural background shaped this a lot because architects don’t design in one shot. Real design is iterative. Some parts of the process are highly repetitive and benefit from automation. Other parts are sensitive, contextual and need very direct human control.
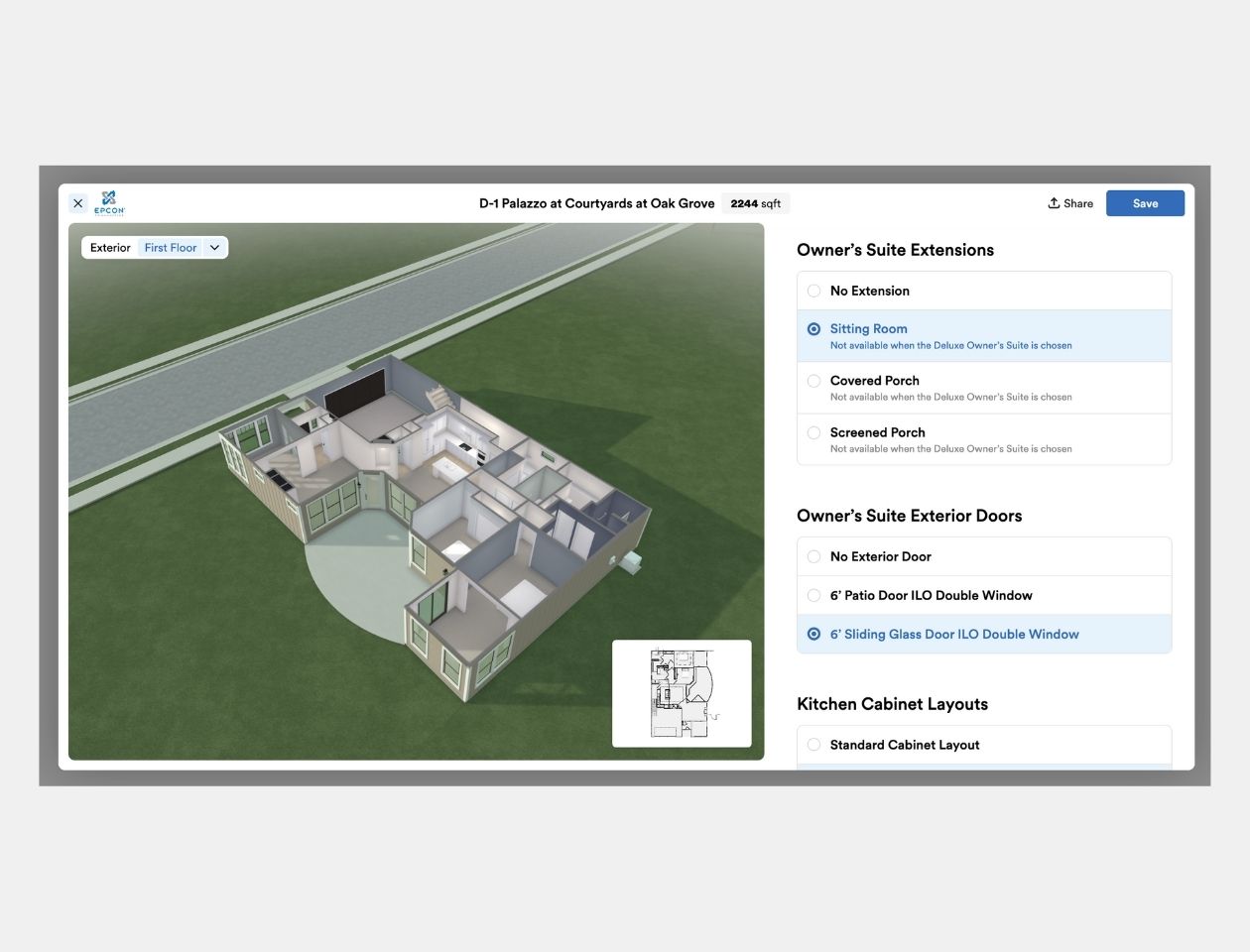
That made me skeptical of one-shot image generation as a product model from the beginning. Design tools should let the user inspect, steer, revise and intervene. An autoregressive setup is much closer to that way of working. It can generate incrementally, which makes it easier to imagine systems where the designer stays in the loop instead of being replaced by a single opaque output.
Real home design is iterative and an autoregressive setup is closest to that way of working. It can generate incrementally, which makes it easier to imagine systems where the designer stays in the loop. For me, that was a product principle as much as a modeling principle.
For me, that was a product principle as much as a modeling principle. The goal wasn’t autonomous design. The goal was to build an AI layout model that can participate in home design the way good software does: by making repetitive decisions easier while keeping authorship and judgment with the designer. We can imagine a future where BIM-native outputs can feed downstream agentic systems for iterative, human-in-the-loop refinement.
Q: Once the representation worked, what did it unlock beyond floor plan generation?
A: That was one of the most exciting parts. Once the representation became tight enough, it became useful for more than just one task.
The same underlying setup could support both understanding and generation. In encoder-only mode, you can embed rooms for retrieval, clustering, structural comparison and plan-library analysis. In encoder-decoder mode, you can generate room contents conditioned on the envelope. That means the system is no longer just a layout generator. It becomes a more general design-intelligence layer.
To me, that’s a much bigger opportunity. Now you can imagine tools that retrieve similar rooms, compare design precedents, organize plan libraries, generate candidate layouts and eventually combine those capabilities into more interactive workflows. That’s when the work starts to look less like a single model demo and more like a foundation for broader AI home design systems.
And I think that foundation can scale much further. Layout generation is only the first visible application. The more important thing is that once you have a faithful BIM-native representation, you can build multiple capabilities on top of it: retrieval, editing, co-design, iterative refinement and eventually more agentic systems that still remain grounded in real building structure.
At the same time, I don’t think the future is just “make the model bigger.” The real work is extending the representational discipline to harder problems: vertical conditions, multi-room dependencies, MEP and larger-scale reasoning across the building. Those are still genuinely hard problems. But the encouraging part is that the representation gives you a foundation that can grow into them instead of starting over for each workflow.
So when I think about the future of GBM, I don’t think of a single floor plan generator. I think of a shared structural language for design software — one that lets more intelligent tools participate in the workflow without losing contact with construction reality.
FAQs
What is BIM-native data?
BIM-native data is building data that keeps the structure of the design intact instead of flattening it into an image or loose abstraction. It preserves things like room type, wall structure, openings and wall-referenced objects so the result stays editable, valid and usable in home design workflows.
What does “representation” mean in AI home design?
In AI home design, representation means the way a building or room is encoded so a model can learn from it. If that representation loses the geometry, topology or semantic relationships that make a layout architectural, the model may still generate something plausible-looking but it won’t hold up in a BIM workflow.
What is tokenization in a building model?
Tokenization in a building model means Higharc’s process of breaking a room down into structured units the model can process as a sequence. Those units can represent things like room type, layout attributes, walls, doors and windows, and room contents, with each token tied to a logical building element rather than an arbitrary chunk of data.
What does autoregressive mean in layout generation?
Autoregressive layout generation means the model generates a layout step by step rather than all at once. That makes it easier to support interactive design workflows because the system can generate incrementally while still leaving room for inspection, revision and human intervention.
What is positional encoding?
Positional encoding is a way to add word-order information to a Transformer’s input so the model can tell where each token appears in a sequence. Transformers process tokens in parallel and do not inherently know order, so positional encoding injects that information directly into the token embeddings.
How does positional encoding work in text?
In text, positional encoding gives each token both a token embedding and a position-based vector. In the classic Transformer setup, that position vector is built from sine and cosine functions at different frequencies and added to the token embedding, which helps the model preserve token order and relative distance.
See Higharc in action
Discover how Higharc can empower your team to conquer change, modernize your buyer experience, and decrease cycle times.
Book a demo



.png)
%20(1260%20x%20960%20px).jpg)



.png)



.jpg)








%20(1260%20x%20960%20px).jpg)

.jpg)

.jpg)



















