.png)
Some innovative builders are using generic AI to produce floorplans early in the design process, when creativity is more important than precision. Yet although large language models (LLMs) and image generators may quickly produce layouts, those plans rarely hold up in real-world workflows because they’re based on pixel groupings, not real-world geometric constraints.
We approached the challenge from a different angle: our team encoded BIM-native building data more like language, as structured tokens that preserve geometry and element relationships; then trained the model on architectural composition directly. That approach made it possible to generate layouts within real building constraints from the start.
The resulting AI layout system is Higharc’s Generative Building Model (GBM). It’s built for real-world homebuilding environments that depend on BIM data, geometry constraints and downstream coordination. When we set out to build it, we focused first and foremost on representing buildings correctly. Instead of treating rooms as images or loose geometric abstractions, we represent walls, openings and room contents as explicit building elements within a BIM-driven workflow. We call this tokenizing buildings.
The key benefit of Higharc’s AI layout approach is that by respecting geometric constraints, circulation efficiency, room adjacencies and relationships between building elements from inception, plans can reliably be implemented without requiring downstream corrections to AI errors.
Jump to the technical explainer.
FIGURE 1: Overview of Higharc's Generative Building Model (GBM) pipeline.
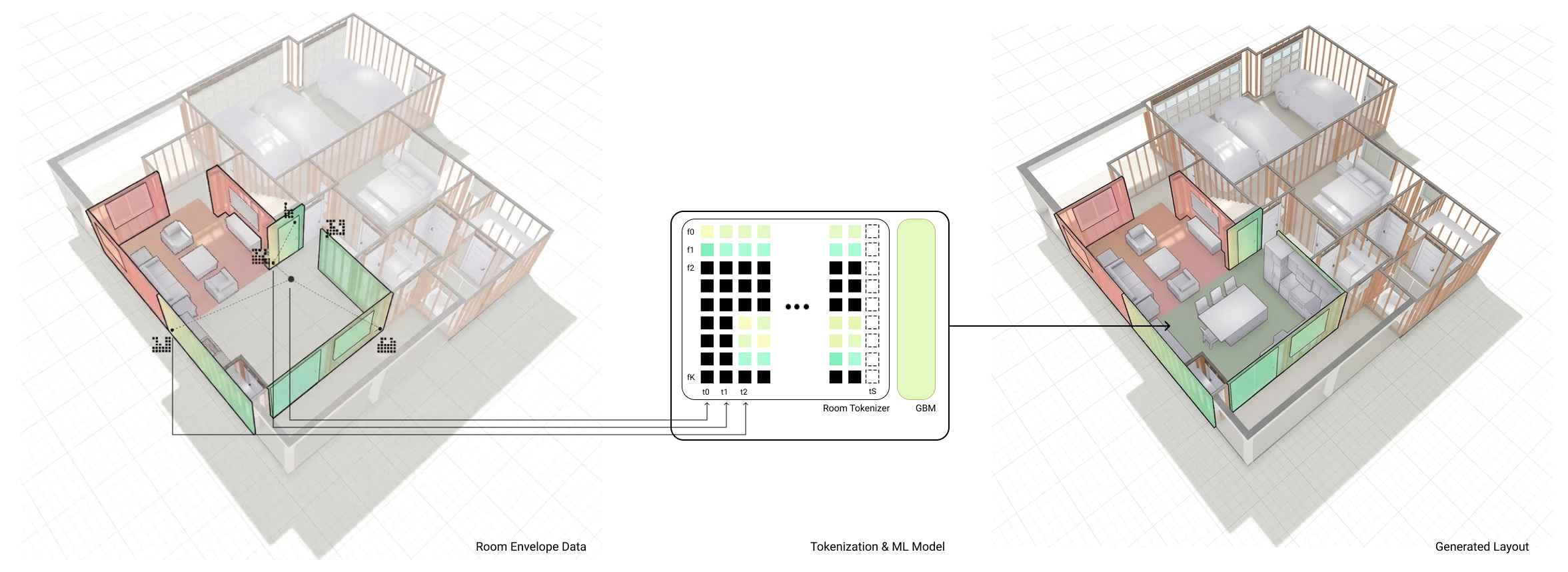
Table of contents
- Key takeaways
- Why AI layouts fail in homebuilding
- From BIM-native room data to reusable design intelligence
- Tokenizing buildings for AI floor plan generation
- How building tokenization works
- One system, two capabilities
- Measuring layout quality
- Tokenizing buildings: technical explainer
Key takeaways:
- Generative layout systems often fail because geometry and constraints aren’t enforced during floor plan creation.
- Higharc applies a language-model idea to building data: by encoding BIM-native rooms as structured tokens, GBM can learn architectural composition patterns the way language models learn syntax.
- Tokenizing buildings gives GBM an explicit room description built from walls, openings, room type and contents, so layout generation happens with real geometric and topological constraints from the start.
- An encoder–decoder architecture built on that representation supports both room analysis and plan generation using the same underlying logic.
- Training on BIM-native room data extracted from thousands of processed home files and 75,720 room samples improves performance and reduces downstream rework.
- Because room analysis, plan creation and future tools share the same building logic, new capabilities remain grounded in construction reality.
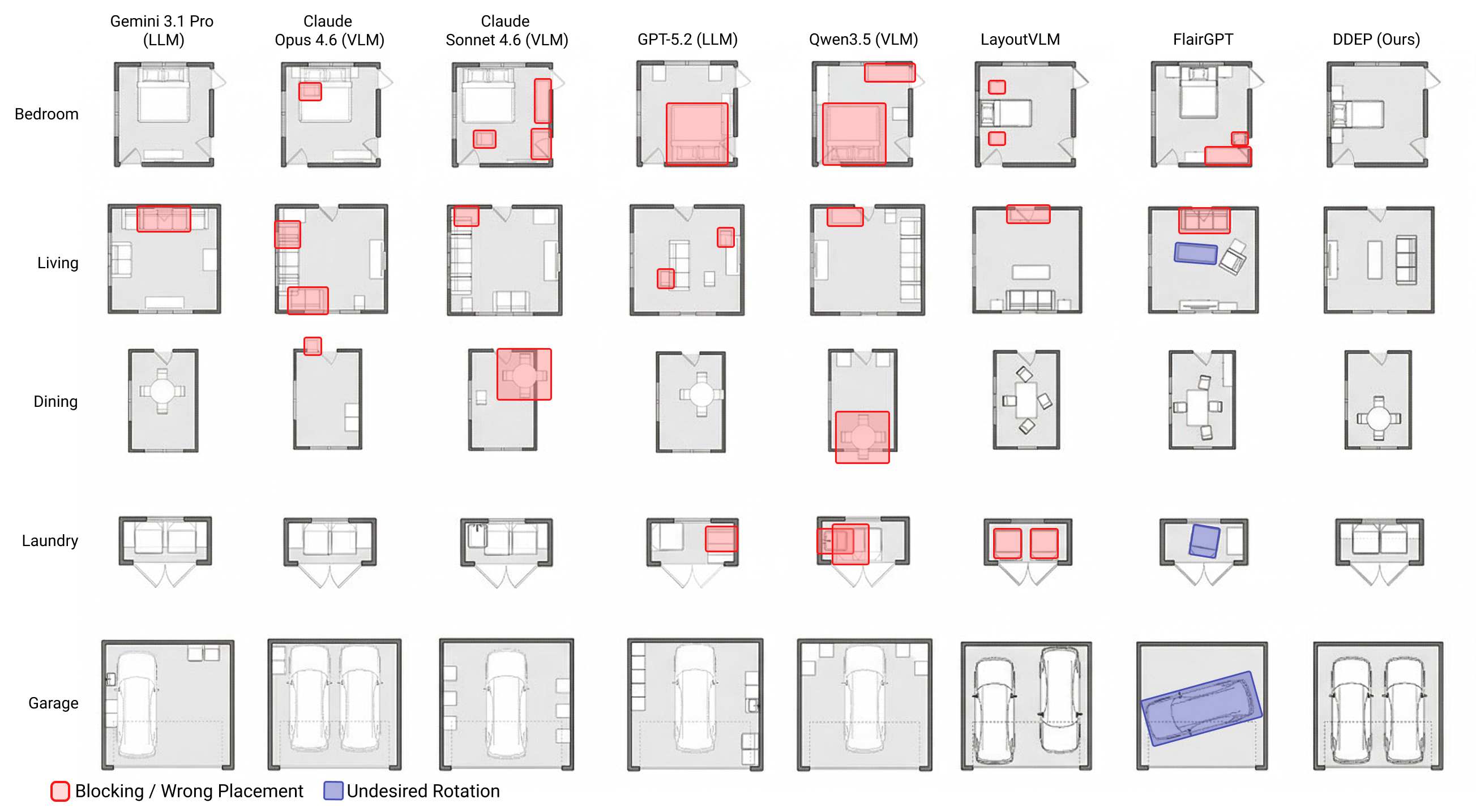
Why AI layout systems fail in homebuilding
FIGURE 2: Qualitative comparison of AI-generated room layouts across five methods and three room types (kitchen, master bedroom, bathroom).

AI models can quickly generate floor plans that look convincing at a glance. But in a BIM-driven workflow, where designs have to respect real geometry, constraints and downstream editability, “looks right” isn’t the same as “works.”
Generative systems create room layouts without attention to interconnected entities and:
- Miss clearances or block circulation corridors
- Place elements without proper wall arrangements
- Struggle when a room falls outside expected conditions
- Require manual cleanup before they can move forward
Learning-based systems generate relatively natural-looking rooms, but when a space departs from the typical patterns the model was trained on, plans lose architectural coherence because constraints aren’t enforced during generation.
Language- and image-based models make room configurations easier to prompt. However, they generate images based on the statistically most likely pixel grouping and have no underlying construction intelligence. Without true geometric grounding, they can’t consistently enforce buildability during plan generation.
Furthermore, when it comes to creating layouts, generic AI models aren’t steerable or editable. Because images are static by definition, every change requires a rerun, which hinders flexibility and velocity.
However, for operating homebuilders, AI-driven floor plan generation needs to reduce work at the front of the process, not introduce ambiguity that manifests later.
That's why Higharc took a different path — by starting with how buildings are actually represented.
From BIM-native room data to reusable design intelligence
FIGURE 3: Training data construction pipeline.
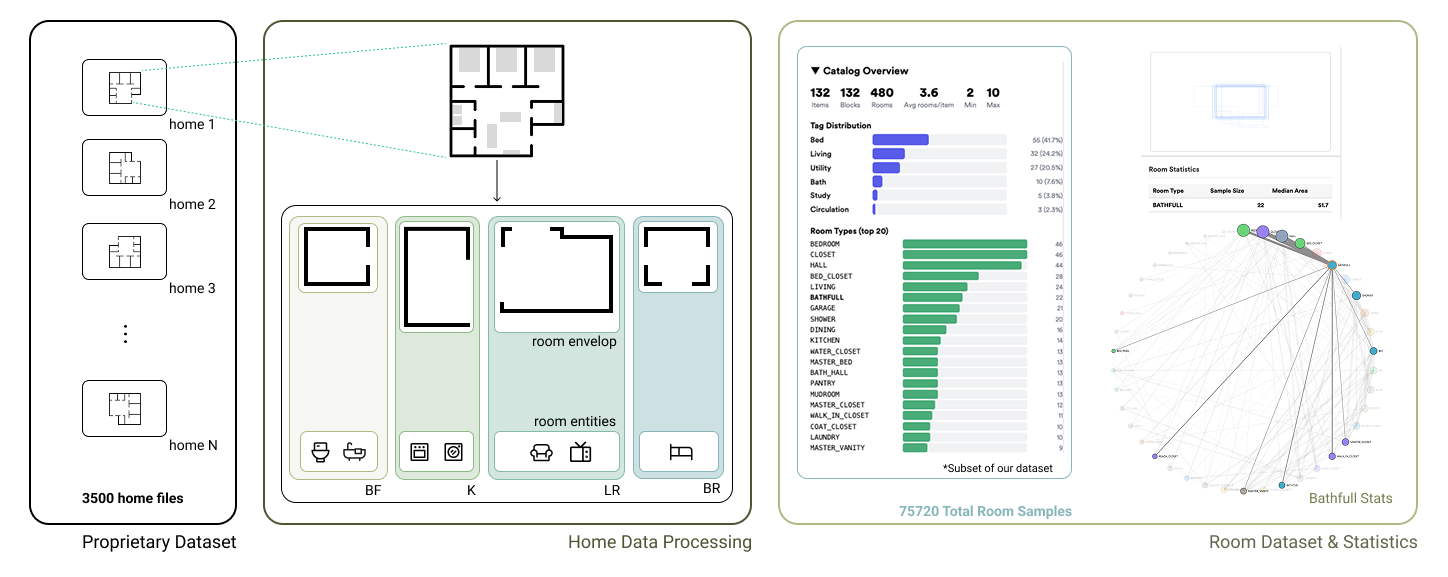
Across large builders, another pattern becomes clear. Design intelligence accumulates over time, in plan libraries, product lines and thousands of completed homes. Yet in CAD systems, that experience isn’t recorded or reflected in the tooling layer. It lives in prior plans, review cycles and in the heads of designers who have to re-input it again for every design they create.
Instead of treating each AI layout as a one-off generation task, Higharc’s AI system learns from structured BIM-based building data derived from approximately 3,500 home files and 75,720 room samples — and encodes that knowledge directly into how rooms are represented.
Tokenizing buildings for AI floor plan generation
To understand why this architecture works, it helps to start with the modeling idea that shaped it.
Represent buildings like language for the model
FIGURE 4: From hierarchical BIM data to sequential token representation.
![Left: nested box diagram showing the BIM hierarchy (Building → Levels → Rooms → Entities). Right: two token sequences— an envelope sequence ([CLS] [Room Type] [Layout] [Wall 1] ... [Door 1] [Window 1] ... [EOS]) and an entity sequence ([SOS] [Vanity] [Toilet] [Tub] [Towel Hook] [EOS]).](https://cdn.prod.website-files.com/65894b1cf3fc835901ce3212/69cd6823df6d8d5112dc4cf2_FIG%204%20sequence.png)
The starting point for this work was a simple but consequential question: what if building data could be understood more like language? Modern generative models became useful in large part because text can be broken into structured tokens that preserve meaning across multiple levels, from paragraphs to sentences to words. We began wondering whether BIM and parametric building data could be treated the same way.
Although architecture is inherently spatial, the underlying data is also deeply structured: buildings contain levels, levels contain rooms, rooms contain walls, openings, casework and furniture, and all of those elements carry geometric and semantic relationships. If that structure could be re-expressed as a sequential representation without losing its hierarchy or spatial logic, then a model could learn buildings the way language models learn syntax and grammar.
That idea led to the core hypothesis behind GBM and Data-Driven Entity Prediction (DDEP): if we tokenized BIM-native data in the right way, a Transformer could learn patterns of architectural composition and predict what should come next. The challenge was not simply to flatten a room into a sequence, but to preserve topology, geometry, containment and references between elements.
In other words, the problem was representational: could we turn buildings into a token space that was sequential enough for modern generative models, yet structured enough to remain faithful to architecture? Once that was possible, predicting the next most probable entity in a room started to look much more like next-token prediction in a domain-specific language of buildings.
What tokenizing buildings means in practice

In practice, tokenizing buildings means representing a room through the building elements that define it. Walls, doors, windows, room type and room contents (such as furniture, casework and fixtures) are encoded directly as BIM-native elements, each with the dimensions, properties and placement details needed for layout.
Those elements are then converted into structured tokens. Each token represents one part of the room — such as a wall, a window or a piece of casework — along with its size, position or type. The result is an explicit room description that preserves geometry and relationships between elements.
Because the information needed to produce a buildable floor plan is already present in the data, the model can generate layouts within the room’s actual constraints from the start. That keeps the synthesis process aligned with how rooms are designed, reviewed and built in homebuilding workflows.
How building tokenization works
(For readers who want a deeper architectural breakdown, a more detailed technical explainer follows below.)
FIGURE 5: Structure of the sparse attribute-feature matrix used by GBM.
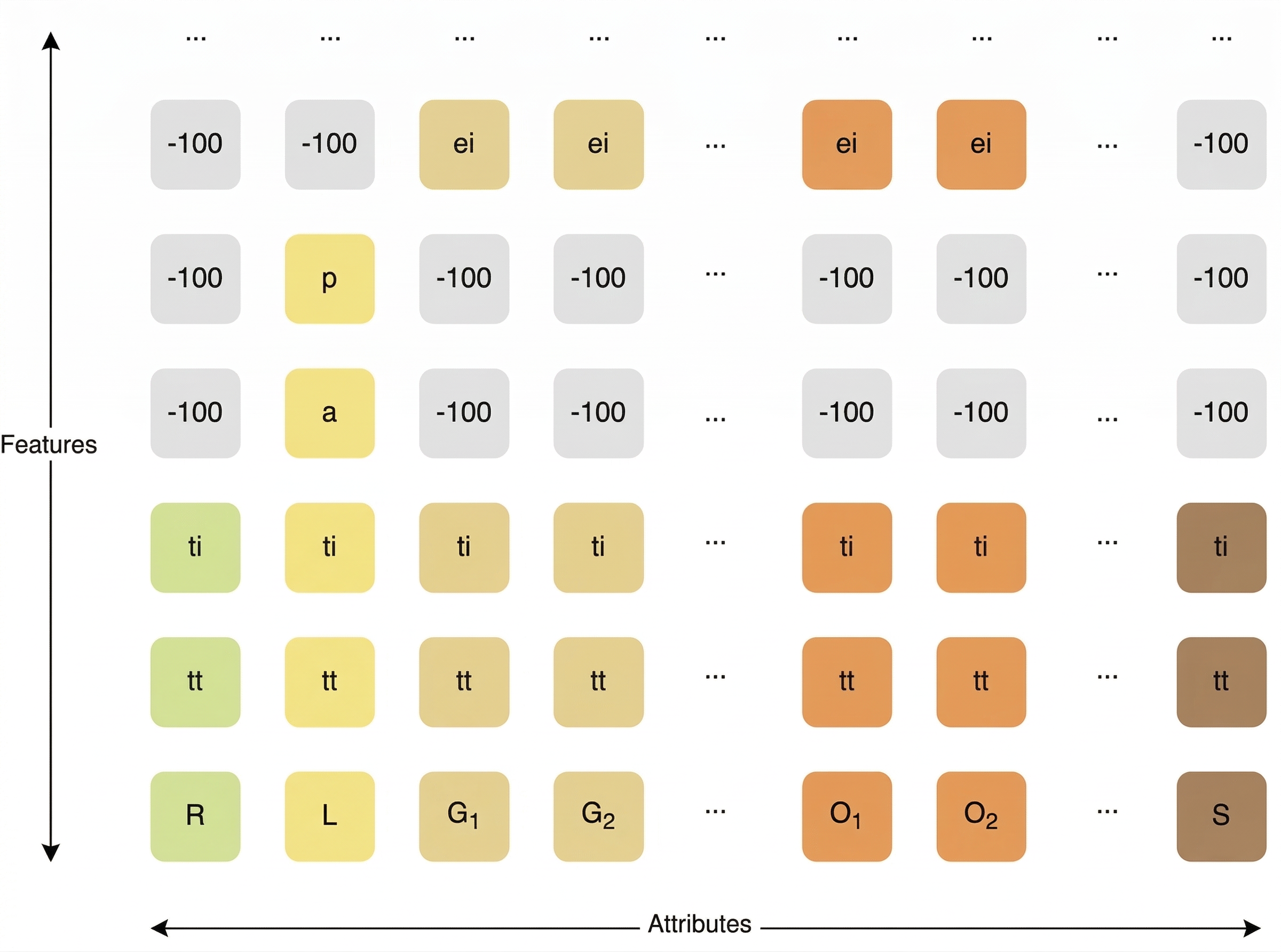
A matrix diagram with "Features" on the vertical axis and "Attributes" (i.e., BIM-Token Bundles) on the horizontal axis. Columns correspond to token types: R (Room type), L (Layout), G1, G2 (walls/geometry), O1, O2 (openings), and S (special/sentinel). Inactive cells are filled with the sentinel value −100.
At a high level, Higharc’s system separates room structure from room contents and processes each step in order using a purpose-built architecture designed for homebuilding AI layouts.
System structure
Start with the room properties (type, area) and envelope
- The system takes the room’s envelope as input
- Walls, doors, windows and overall geometry are provided as explicit building data
- This defines the spatial constraints the room must respect
Encode the room structure
- An encoder processes the room envelope
- Its role is to build an internal representation of the room’s structure
- No room contents are generated at this stage; the system establishes what the room allows
Generate the room contents
- A decoder generates room contents based on that structural understanding
- Contents include casework, fixtures, and furniture
- Each element is generated relative to specific walls, with defined offsets, sizes and orientations
Use wall-referenced placement
- Element placement considers distance along the wall, depth into the room, size and orientation
- This keeps geometry consistent and avoids common design issues like overlaps, clearance violations or blocked circulation
The encoder and decoder are built on a Transformer, which enables the system to process walls, openings and room contents together while preserving how those elements relate to one another.
One system, two capabilities
Because the encoder and decoder operate on the same building representation, the system supports two practical modes: room analysis and AI layout generation (and editing).
FIGURE 6: GBM's encoder-decoder Transformer architecture.
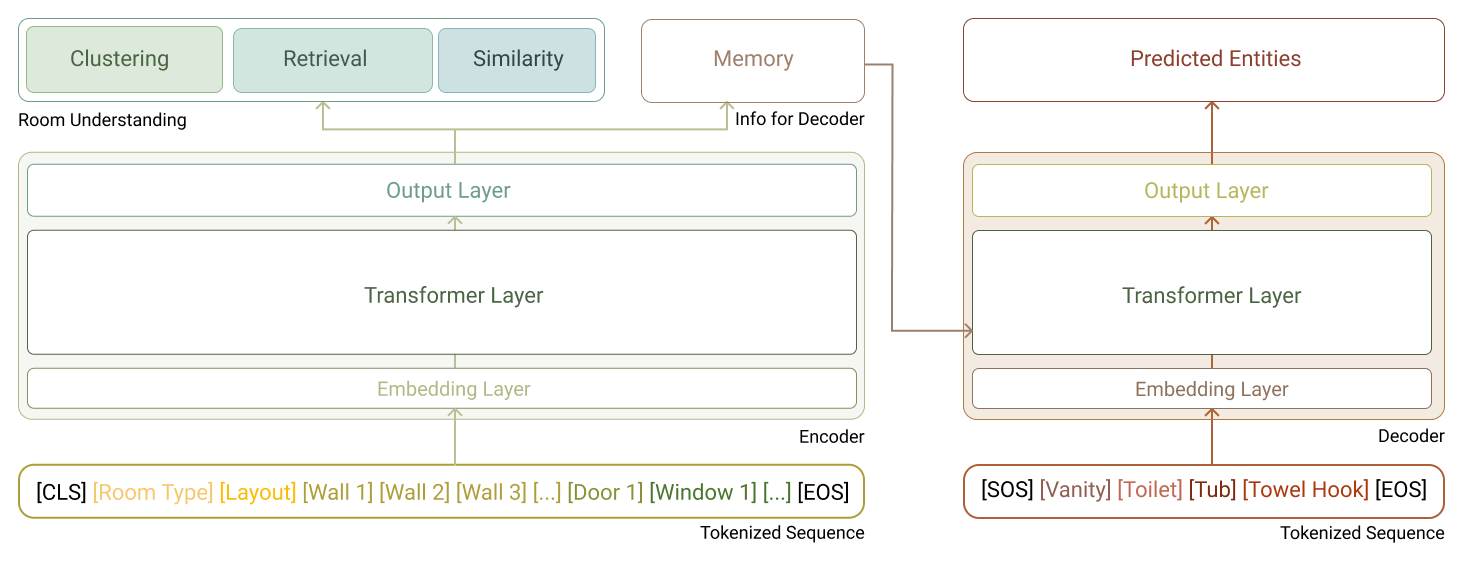
Room analysis (encoder-only mode)
When used without the decoder, the encoder processes a room envelope and produces a compact representation in latent space. In practice, this facilitates design comparison, floor plan clustering and retrieval of semantically similar rooms across large plan libraries. The model isn’t generating content in this mode; it’s understanding room geometry and constraints.
AI layout generation
When the decoder is activated, the system generates and edits room contents conditioned on the encoded envelope. Elements are produced sequentially, with placement defined relative to the room’s walls and openings. Because generation is grounded in the same semantic representation used for comprehension, constraints are enforced during learning rather than corrected afterward. In addition, the home designer using the AI has the construction knowledge from tens of thousands of rooms at their disposal. This is what enables Higharc’s layouts to move toward construction readiness without downstream rework.
Both capabilities rely on the same Transformer architecture and the same building tokenization scheme. The difference lies in application: the system can either understand and organize room arrangements or produce — and edit — configurations within those constraints using the same underlying intelligence.
Measuring layout quality
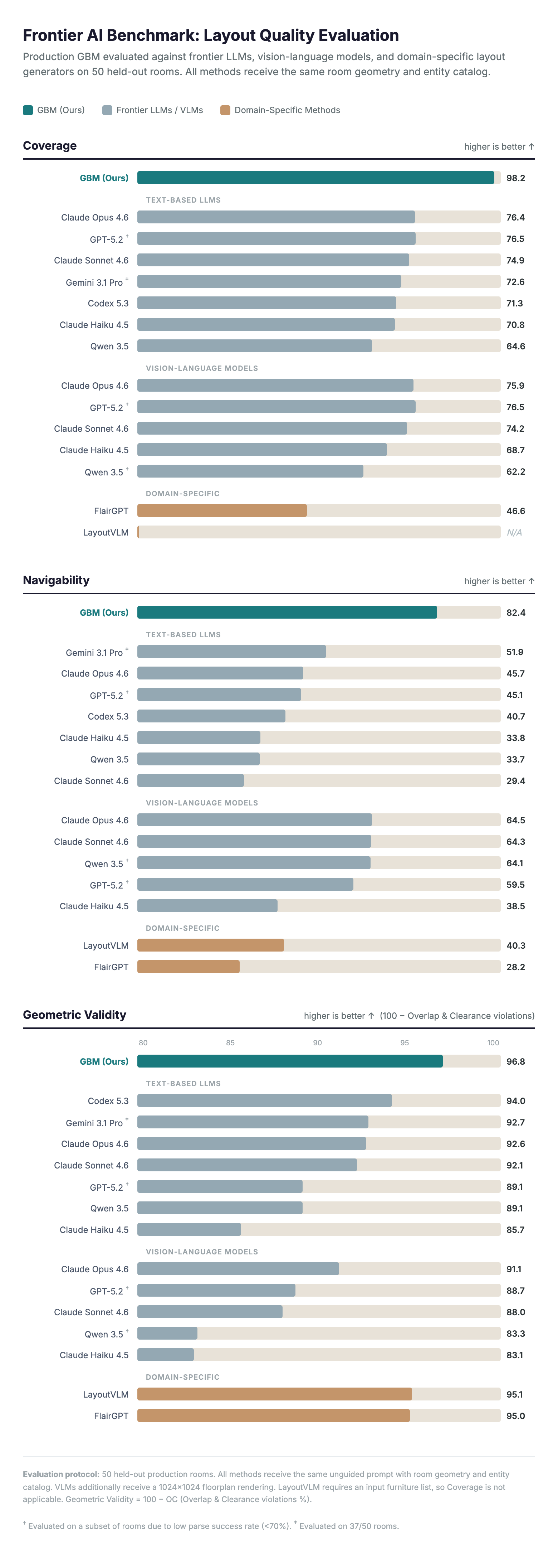
A room layout that looks plausible in a rendering isn't necessarily one that works on a jobsite: furniture might overlap, doors might be blocked, or required fixtures might be missing entirely. To evaluate whether our AI-generated layouts actually held up in real homebuilding workflows, we measured three things: whether the room had what it needed, whether you could move through it and whether the geometry was physically valid.
We benchmarked GBM against the strongest available AI systems — frontier language models with and without vision enabled (Claude Opus 4.6 or Gemini 3.1 Pro, for instance), vision-language models that can also see the floorplan and purpose-built layout generators (FlairGPT, LayoutVLM).
Coverage: does the room have what it needs?
Each room type comes with an expected inventory. A primary bathroom needs a vanity, toilet and tub or shower while a kitchen needs countertops, appliances and cabinets. Coverage scores a layout against that inventory, rewarding completeness and penalizing extraneous items.
GBM achieved 98.2% coverage, meaning it placed nearly every required element in every room. The best frontier LLM reached 76.4%. Domain-specific methods designed for layout generation scored as low as 46.6%. These metrics underscore a fundamental difference: GBM's tokenization explicitly encodes exactly which entity types a room requires, and the decoder is trained to satisfy that program during generation.
Navigability: can you walk through the room?
Navigability uses pathfinding to evaluate whether a person can walk from every door to each key destination in the room — bed, shower, kitchen counter — and measures how direct those paths are.
The score combines two factors: success rate (what fraction of destinations are reachable at all) and detour factor (how much extra distance is required to get there). A room with clear, direct paths scores high, while a room where furniture blocks the door or forces long detours scores low.
GBM scored 82.4 on navigability. The best vision-language model reached 64.5, and most text-only LLMs scored below 52. The advantage comes from wall-referenced placement: because GBM positions each element relative to a specific wall with explicit offsets, it naturally preserves circulation corridors and door clearances during generation.
Overlap and clearance: does everything actually fit?
The final check is geometric validity. Do furniture pieces overlap each other? Do cabinets clip through walls? Is there enough clearance for doors to swing open? These violations might be invisible in a rendered image, but they make a layout unbuildable.
This metric aggregates entity-to-entity overlaps, wall boundary violations and door clearance intrusions using exact polygon geometry instead of pixel approximations.
GBM produced the fewest geometric conflicts at 3.2%. Frontier language models ranged from 7% to 9%, while some learning-based baselines exceeded 16%. Domain-specific layout methods performed better here (around 5%) but at the cost of placing far fewer items — it's easy to avoid overlaps when the room is half empty.
The pattern across baselines
The benchmark revealed a consistent tradeoff that every competing approach falls into. Frontier LLMs can select reasonable furniture, but they struggle with spatial reasoning — items overlap, block doorways or leave no room to walk. Vision-language models improve navigability by seeing the floorplan but introduce more geometric violations in the process. Domain-specific methods keep geometry cleaner but miss large portions of the required inventory.
Higharc’s Generative Building Model is the only system that performs well on all three axes simultaneously. The tokenization encodes the structure of the room — geometry, topology and required entities — so the decoder operates within an explicit architectural program during generation.
FIGURE 7: Frontier AI benchmark: layout quality evaluation on 50 held-out production rooms.
If developing this kind of AI interests you, we want to hear from you — check out our career page.
Generative Building Model: technical explainer
TL;DR
Higharc’s Generative Building Model (GBM) combines:
- BIM-native tokenization
- Sparse structured feature matrices
- Mixed-type embedding of categorical and continuous attributes
- A shared Transformer backbone supporting both embedding and generation modes
The result is layout synthesis grounded in an explicit structural context.
Representation determines layout quality
The idea behind Higharc’s AI layout came from the same insight that made large language models effective: a model can learn complex structure when the underlying data is represented as meaningful tokens. In the context of building design, that means representing rooms through the elements builders actually work with — walls, openings, casework, fixtures and room attributes — instead of pixel groupings or loosely structured geometry.
This led to the Generative Building Model (GBM): a Transformer architecture built around a normalized BIM-native tokenization scheme.
How GBM operates
Figure 2 — Model Overview
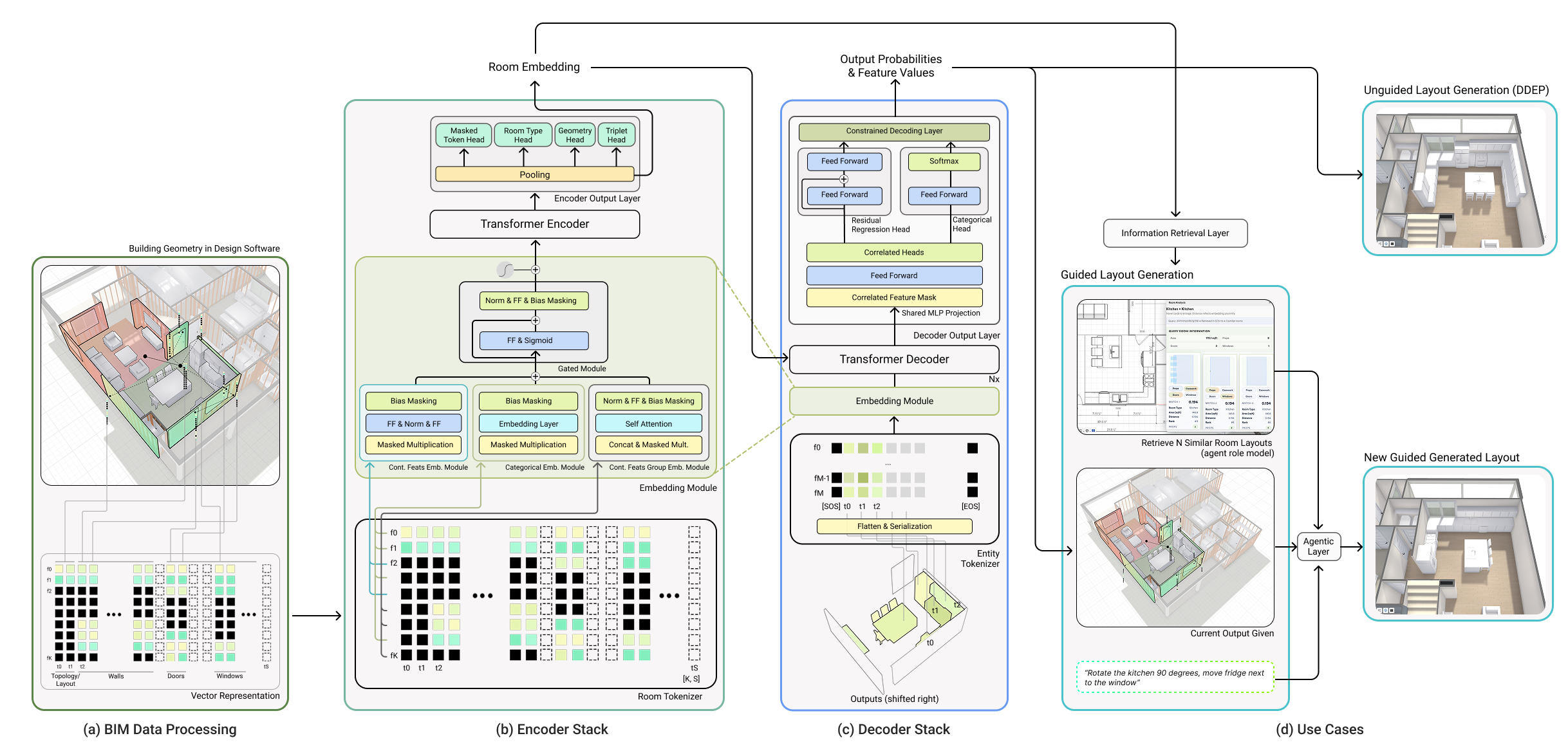
GBM operates at the room level. Each room is deconstructed into two components:
- Envelope: topology, layout attributes, walls, doors, windows
- Contents: props (furniture) and casework entities
We define the full room as: r = (renv, rent).
The envelope encodes structural and geometric constraints. The contents must conform to those constraints. This deconstruction mirrors homebuilding design workflows: the structure defines the solution space; entities populate it.
Formal task definition
GBM supports two operating modes built on this deconstruction.
Encoder-only mode
The objective is to map the room envelope to a compact embedding:
zˆ(renv) ∈ℝd
The embedding captures room type, topology, wall configuration and opening structure. It preserves geometric and semantic relationships between rooms and supports retrieval, clustering, structural comparison and plan library analysis.
Encoder-decoder mode (Data-Driven Entity Prediction, DDEP)
In Data-Driven Entity Prediction (DDEP) mode, the model predicts and places room elements one at a time, conditioned on the encoded room structure.
The encoder processes renv and produces a contextual structural memory. The decoder then autoregressively generates the entity sequence:
rent = (P, C)
Each entity is emitted as a structured token containing categorical attributes and wall-referenced continuous parameters.
Generation is conditioned exclusively through cross-attention to the encoded envelope. Because placement parameters are defined relative to explicit structural elements, entity predictions are made within the room’s constraint space.
BIM tokenization: ordered sequences and structured feature matrices
GBM operationalizes the representation of a room by converting it into two ordered sequences of structured BIM-Token Bundles:
- An envelope sequence for the encoder
- An entity sequence for the decoder
These sequences form the structured interface between BIM data and the Transformer backbone.
Envelope sequence (encoder input)
The envelope sequence contains structural information only:
- Classification token (CLS)
- Room topology token (room type)
- Layout token (area, perimeter, global scalars)
- Wall tokens
- Door tokens
- Window tokens
- End-of-sequence token (EOS)
- Padding up to a fixed maximum length
The ordering is fixed and deterministic. It encodes structural hierarchy: room-level semantics first, boundary geometry next, then the openings attached to that boundary. Furniture and casework are excluded from this sequence.
Entity sequence
The decoder operates on a separate contents-only sequence:
- Start-of-sequence token (SOS)
- Entity tokens (props and casework)
- End-of-sequence token (EOS)
- Padding
Each entity token represents a single room element (bed, cabinet, vanity, appliance, etc.) and encodes both its categorical type and wall-referenced placement attributes.
Formally, each entity q is parameterized as (e_q, t_q, δ_q, s_q, ρ_q), where e_q is the index of the supporting wall, t_q ∈ [0, 1] is the normalized position along that wall, δ_q is the lateral offset (depth into the room), s_q encodes width, height and depth and ρ_q is the rotation angle (props only). This wall-referenced coordinate system means every placement is defined relative to the room’s geometry, making entity positions invariant to absolute translation and scale.
Structural context is provided through cross-attention to the encoder memory.
Attribute-feature matrices
Each token sequence is represented as a sparse attribute feature matrix:
- For the encoder: Xenc ∈ℝFenc x Senc
- For the decoder: Xdec ∈ℝFdec x Sdec
Where:
- F = number of possible features
- S = maximum sequence length
Each column corresponds to one BIM-Token Bundle. The first rows contain generic identifiers present for every token: a token type ID and a token ID. Remaining rows encode element-specific attributes.
For the encoder, these include room-level scalars (area, perimeter), wall geometry (edge endpoints, lengths, thicknesses) and opening parameters (normalized wall position, width, corner distances).
For the decoder, rows include entity type, support for edge attachment, wall-referenced coordinates (tq, 𝛿q), size parameters sq and rotation 𝜌q.
Only the feature rows relevant to a token type are active. Non-applicable entries are filled with a sentinel value, yielding a sparse representation.
These sparse matrices are mapped to dense token embeddings by the mixed-type embedding module.
Mixed-type embedding
After converting the room into sparse attribute–feature matrices Xenc and Xdec, GBM maps those structured features into dense token embeddings suitable for the Transformer.
Each BIM-Token Bundle combines:
- Categorical identifiers (token type, token ID, wall condition, entity category)
- Scalar continuous values (area, length, width, normalized wall position)
- Grouped continuous values (edge endpoints, thickness pairs, corner distances)
A mixed-type embedding module projects these heterogeneous features into a shared embedding space. The same mechanism is used for both encoder and decoder; they differ only in which feature rows are active.
Feature-wise embedding and masking
Each feature row is embedded independently before aggregation:
- Categorical features use learnable embedding tables with dedicated padding entries.
- Scalar continuous features are projected through small feedforward networks (MLPs) into the shared embedding dimension.
- Grouped continuous features (e.g., coordinate pairs or thickness pairs) are processed by a lightweight subnetwork that embeds each scalar, aggregates across the group (via pooling or attention), and projects to the same dimension.
Not every feature row applies to every token type. Non-applicable entries are filled with a sentinel value and masked so they contribute zero to the final embedding.
Formally, for feature row f at sequence position s: m(f,s) = 𝟙[X(f,s) ≠ −100]; ũ(f,s) = m(f,s) · E_f(X(f,s)); e_s = Σ_f ũ(f,s). The indicator mask m zeros out inactive features; each active feature is embedded by its type-specific projector E_f; the final token embedding e_s is the sum over all active feature embeddings at that position.
The final token embedding is the sum of all active feature embeddings for that token, producing one dense vector per BIM-Token Bundle.
The decoder uses the same embedding architecture with decoder-specific feature definitions, including entity type, supporting wall index, wall-referenced coordinates (tq, 𝛿q), size parameters and rotation. Masking and aggregation follow the same feature-wise logic, yielding a dense sequence of decoder token embeddings in the same embedding space as the encoder.
Transformer backbone and operating modes
GBM uses a standard Transformer encoder-decoder backbone. Architectural differentiation lies in the tokenization and mixed-type embedding layers. The same backbone supports two operating modes: encoder-only for room embeddings and encoder–decoder for conditional entity generation.
Encoder-only mode (room embedding and retrieval)
In encoder-only mode, the input is the envelope token sequence. The encoder applies stacked self-attention and feedforward layers to produce contextualized token representations.
The embedding at the CLS position serves as the pooled room representation. This vector encodes room type and layout structure, wall topology and opening configuration, and supports similarity search, clustering and retrieval across plan libraries.
Encoder–decoder mode (Data-Driven Entity Prediction)
In encoder–decoder mode, the encoder produces a fixed structural memory from the envelope sequence. The decoder generates the entity sequence autoregressively, applying causal self-attention over previously generated tokens and cross-attention to the encoder memory.
At each step, the decoder predicts both discrete labels and continuous placement parameters, including entity type, supporting wall index, wall-referenced coordinates (tq, 𝛿q), size parameters and rotation where applicable.
Because predictions are conditioned on the encoded structural memory and expressed in wall-referenced coordinates, entity placement remains aligned with the room’s geometric constraints during generation.
Training data and experimental context
GBM is trained on BIM-native room data extracted from roughly 3,500 processed hom files, spanning 75,720 room samples across typed spaces such as kitchens, bathrooms, offices and garages. Each room is converted into envelope and entity token sequences as described above.
Although the total token volume is small relative to web-scale language models, the dataset reflects real production geometries and furniture programs. Results indicate that representation alignment with BIM structure plays a larger role than model scale.
Layout quality evaluation
Figure 3 — ddep qual
Layout generation is evaluated along three production-relevant axes:
- Coverage: Measures whether the required room-type inventory is satisfied while penalizing extraneous elements.
- Navigability: Evaluates door-to-target reachability and path efficiency using collision-aware shortest-path analysis.
- Overlap and clearance: Measures geometric violations, including entity overlap, clearance intrusions, and wall boundary violations using exact polygon geometry.
Coverage is computed per room as Cov = (1/N) Σ [item_score + group_score − extraneous_penalty], where item scores measure required-item placement and group scores handle alternative groups (e.g., bathtub or shower stall). Higher is better; 100 means full inventory satisfaction with no extraneous elements.
Navigability is defined as Nav = 100 × (SR − 0.35 × DF), where SR is the fraction of door-to-target pairs with a valid collision-free path and DF is the mean detour factor (ratio of actual path length to straight-line distance, minus one). The score ranges from −35 to 100. A separate post covers the full metric design.
Overlap and clearance is a weighted composite: OC = w₁·EOF + w₂·GOA + w₃·DCI + w₄·WBV, aggregating Entity Overlap Fraction, Global Overlap Area, Door Clearance Intrusion, and Wall Bounds Violation. All sub-metrics use exact polygon geometry — no rasterization. Lower is better; zero means no geometric conflicts.
On a 50-room held-out benchmark, DDEP achieves 98.2% coverage, 82.4 navigability, and 3.2% geometric violations — compared to 76.4% / 45.7 / 7.4% for the best frontier text LLM (Claude Opus 4.6) and 75.9% / 64.5 / 8.9% for the best vision-language model. Domain-specific methods (FlairGPT, LayoutVLM) achieve lower geometric violations (~5%) but fall well short on coverage (46.6%) and navigability (≤40.3). The pattern across baselines is consistent: frontier LLMs trade spatial precision for coverage, VLMs improve navigability but introduce more geometric violations, and domain methods keep geometry cleaner at the cost of inventory completeness. DDEP is the only system that performs well on all three axes simultaneously.
Encoder embedding behavior
Figure 4 — Clustering
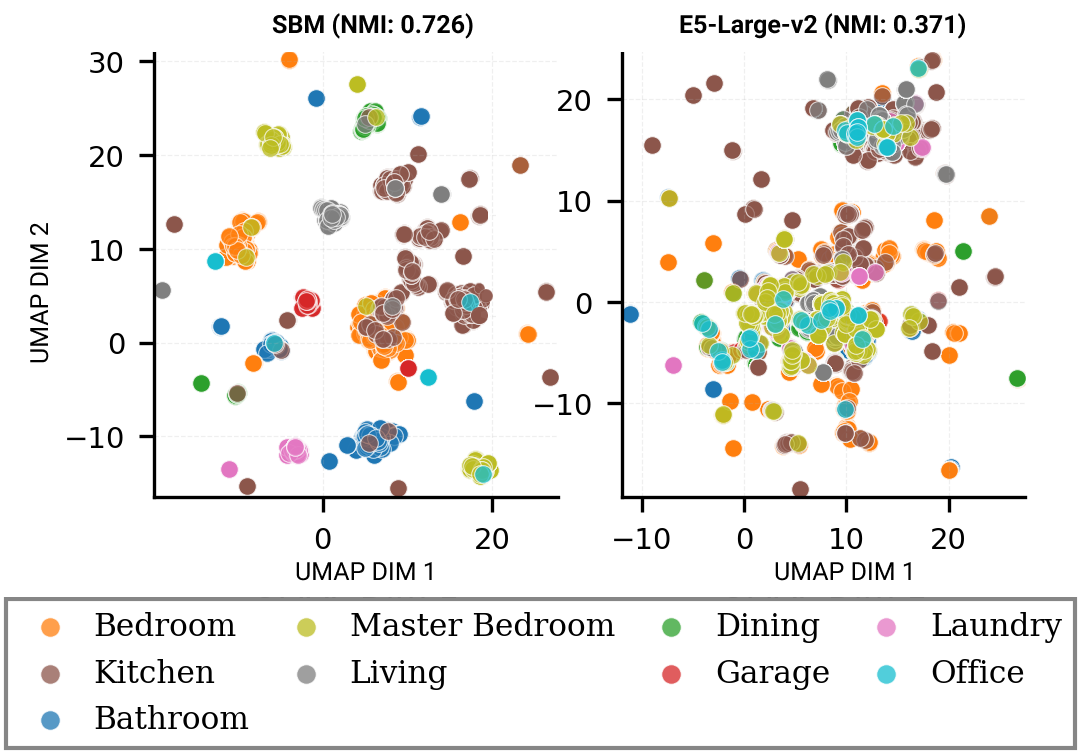
The encoder-only pathway produces geometry-aware room embeddings for retrieval and clustering. Compared to large text embedding models, GBM embeddings:
- Preserve room-type separation more consistently
- Reflect geometric similarity within type
- Better align with entity-level overlap patterns
Text embeddings often rank semantically similar rooms effectively but exhibit weaker structural organization. GBM prioritizes geometric coherence over general semantic similarity.
Limitations and scope
The current scope is room-level residential AI layout synthesis.
Not yet modeled:
- Vertical constraints (e.g., sloped ceilings, elevation changes)
- MEP routing
- Cross-room constraint propagation
The representation is extensible, but the current training data and evaluation focus on production residential rooms.
Interested in joining our AI team? Check out opportunities at Higharc!
Author:
Manuel Rodriguez Ladrón de Guevara is a Senior ML Research Engineer at Higharc, where he works on foundation-style building models over BIM tokens, layout prediction, embeddings, retrieval and agentic systems for design workflows. He holds a PhD in Computational Design focused on AI/ML from Carnegie Mellon University and combines that research background with earlier training in architecture and robotic fabrication, as well as professional architectural practice as a licensed architect in Spain. Before Higharc, he was a Research Scientist Intern at Adobe Research, where his work contributed to ICCV 2023 and ICMEW 2024 publications and patent activity in avatar generation and neural stroke-based image stylization. He is also the co-founder and CEO of Flumio, an AI-and-robotics startup building text-to-fabrication systems. His research spans multimodal learning, graphics, LLMs, spatial reasoning, and AI home design, and he has served as a reviewer for venues including NeurIPS, CVPR, ECCV, ICCV, WACV and CAADRIA.
See Higharc in action
Discover how Higharc can empower your team to conquer change, modernize your buyer experience, and decrease cycle times.
Book a demo
.png)




.png)
%20(1260%20x%20960%20px).jpg)



.png)



.jpg)








%20(1260%20x%20960%20px).jpg)

.jpg)

.jpg)



















